03. [CKA]Workloads & Scheduling
Workload/Scheduling에 대해 알아보자

labels
-
생성된 자원에 대한 key-value dic type으로 라벨링 붙여 넣고,
selector로 필터링해서 자원 조회 가능 -
kubectl get pods -l <key=value>: Selector로 특정 필터링을 한 리소스 자원만 조회 (-l env=prod) -
kubectl get pods --show-labels: pod 정보 조회시 라벨값도 출력 -
kubectl label pod <pod name> <key=value>: pod에 라벨 정보 삽입. (ex. label pod pod-1 env=dev/env!=dev) -
kubectl label pod <pod name> <key>-: pod에 라벨 정보 삭제(key값으로 삭제, label pod pod-1 env-) -
kubectl run nginx --image=nginx --dry-run=client=client -o yaml > get-test.yaml: 실질적으로 pod 생성하지 않는 디버깅용 명령어, metadata에 라벨정보 run 처럼 env로 manifest 정보 입력 가능 -
kubectl label pods --all <key=value>: 모든 pod 에 key=value 태그 달기 (ex. label pods –all status=running)
manifest 파일 생성
- manifest에 생성 시 아래 doc page 에서 확인 가능
- https://kubernetes.io/docs/reference/generated/kubernetes-api/v1.32/
- 하위 필드가 있는 경우 하이퍼 링크로 더 타고 들어가서 어떤 필드값을 채워나갈지 확인 가능 (Pod을 예시로 보면서 확인 가능)
- 그외 강의 material - link
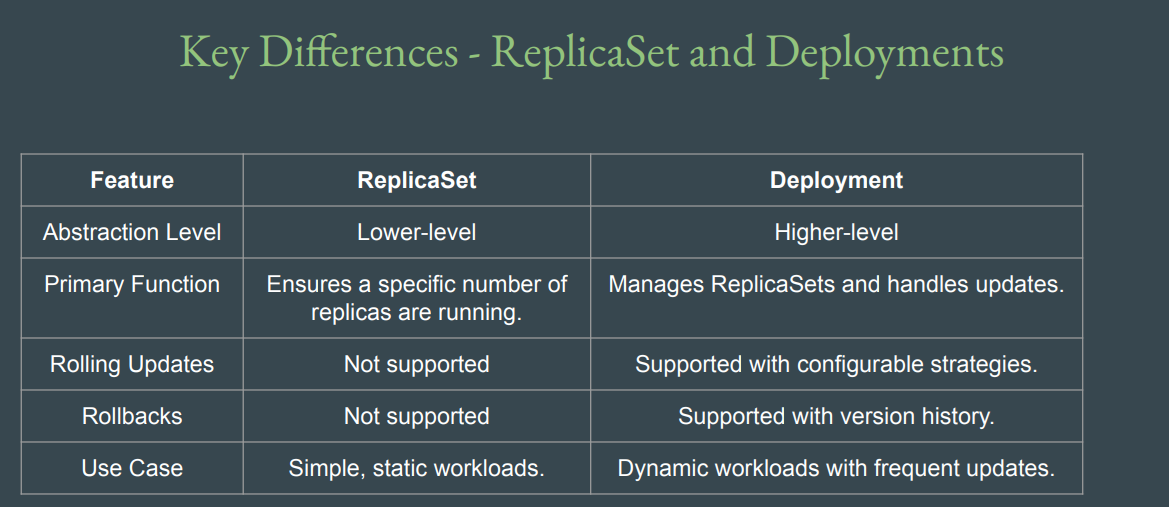
replica
- 동일한 pod
sacle up하면서health 자동으로 관리를 위해 사용 -
kubectl get replicaset: 현재 생성된 replicaset 조회(rs로도 사용 가능) -
kubectl scale --replicas=10 rs/webserver-replicaset: pod scale up -
kubectl apply -f <manifest file>: manifest로 레플리카셋 생성(link, cli로는 생성 x)
replicaset으로 생성된 pod들은 manifest 파일이 업데이트 되어도 자동으로 업데이트가 되지 않음. pod를 한번 삭제하거나 scale 0으로 갔다가 원하는 갯수로 생성해야 업데이트된 pod 생성됨!!!!
replicaset으로 생성된 pod들은 자동 rollback mechanism이 없음
replicaset으로 생성된 pod들은 라벨링 수행시 이전에 생성된 동일한 label의 pod들도 자동으로 관리(rs에 새로운 라벨을 달아서 관리하는게 좋음)
-
kubectl describe rs/<pod name>: 생성된 replicaset pod 정보 조회
deployment
- behind scene에서 replicaSet 관리 + Update(roll out/roll back)을 수행
- 단, deployment 업데이트 후에도 최신 pod를 생성하지 않는다면 existing pod에는 영향을 주지 못함
-
업데이트 수행 시 기존 replicaSet은 새로운 replicaSet이 생성 된 이후에 사용중지 되며 기존 운영중인 서비스에 영향을 주지 않음!
-
kubectl rollout history <deployment/pod-name>: deployment rollout history 확인
-
kubectl create deployment <deployment-name> --image=nginx: deployment-name 생성(생성 시 pods/rs도 자동으로 생성됨을 확인 가능!!!) -
kubectl get deployment: 생성된 deployment 자원 조회 -
kubectl set image <deployment/deployment-name> <image>: deploy된 이미지 업데이트 (set image deployment/nginx-deployment nginx=httpd:latest) -
kubectl rollout undo deployment nginx-deployment: roll back 수행( 위 명령어로 roll out된 내역 undo! ) -
kubectl rollout undo deployment/nginx-deployment --to-revision=<number>: 특정 revision 버전으로 roll back -
kubectl scale --replicas=3 deployment/<name>: deployment로 생성된 pod도 scale 가능
Multiple Worker Nodes
- 워커 노드의 리소스(CPU/Storage)에 따라 Production level에서 워커노드를 생성하고 관리하는 방법에 대해 알아본다
- 워커 노드를 추가하면 workload를 분배하여 load blancing을 수행하여 pod를 적절히 노드에 분배하여 생성이 됨
- 하나의 워커노드를 가지고 있을 경우, 해당 노드에 문제가 발생 시 서비스가 다운되는 문제가 발생되어 Multiple worker 노드로 관리 시 이에 대한 문제를 막을 수 있음
- 워커 노드별 hardware spec이 동일하게 생성하지 않아도 되며, 다르게 설정하는
flexibility제공(ex. worker1 = 2GB RAM, 2 CPU/ worker2 = 4GB RAM, 4 CPU) - 워커 노드 중에 하나가 문제가 있어서 down 되면 pod를 자동으로 다른 worker node로 scheduling 수행
-
kubectl get nodes: cluster 내 연결된 worker node 조회 -
kubectl create deployment nginx-deployment --image=nginx --replicas=3: 3개의 replica를 갖는 nignx image의 deployment 생성 -
kubectl get pods -o wide: 생성된 pod들이 어느 워커 노드에 생성되었는지 확인 가능
Node Selector
- Node들의
Flexibility에 따라 노드별 HW spec이 다를 때, Pod별로 요구하는 HW Spec 요구사항이 다를 수가 있음 - 위와 같은 경우
Node Selector를 활용하여 클러스터 내 pod 배치를 컨트롤 할수 있음 -
node에
label(key=value, ex.size=medium)을 할당해놓고,manifest 파일에 nodeSelector spec을 이 값으로 설정해 놓으면 매칭되는 node에 pod allocation을 수행 -
kubectl label node <node-name> <key=value>: 노드에 라벨값 설정(ex. label node gyyeon-node-eop82 size=medium) -
kubectl label node <node-name> <key>-: 노드에 설정된 라벨값 삭제 kubectl
Daemon Set
- Pod copy가 실행되도록 보장해주는 것이
DaemonSet임 - 새로운 노드를 생성 시 기본적으로 돌아가야할 pod들이 있을때 이를 셋트로 생성되도록 할수 있는 활용 예가 있음( ex. 노드 생성 시 기본적으로 Antivirus라는 pod를 실행하도록 구성해야하는 경우 DaemonSet를 사용)
-
pod의 경우 특정 노드 삭제/crash 발생 시 돌고 있던 pod를 reallocate를 수행하지만 daemonset은 reallocation 없이 하나의 노드엔 하나의 정의된 pod만 수행됨
-
kubectl get daemonset: 생성된 daemonset 조회 -
kubectl apply -f <daemonset manifest file>: link를 참조하여 manifest로 daemon set 생성(CLI로 생성 x)
Node Affinity link
-
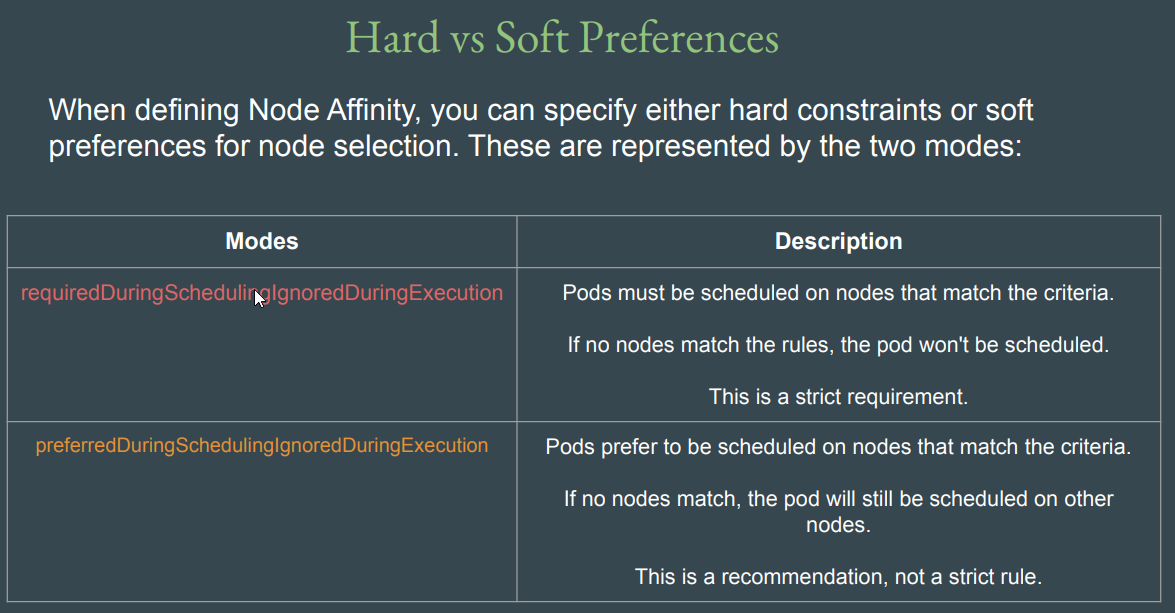
Node Selector의 경우 엄격한 label(key=value) 매칭을 통해서만 node placemnet가 이뤄짐 -
Node Affinity는 Selector에 비해 보다 유연한 표현식을 제공 - 아래와 같은 연산자를 통해 pod scheduling을 제공하며,

- Required/Preferred를 통해 정책도 설정 가능(ex. 엄격/선호로 부드럽게 설정 가능. 아래 Preferred-> Required로 설정 시 AppA는 정확히 Key에 매칭되는 value값이 없기 때문에 스케쥴링 안됨)


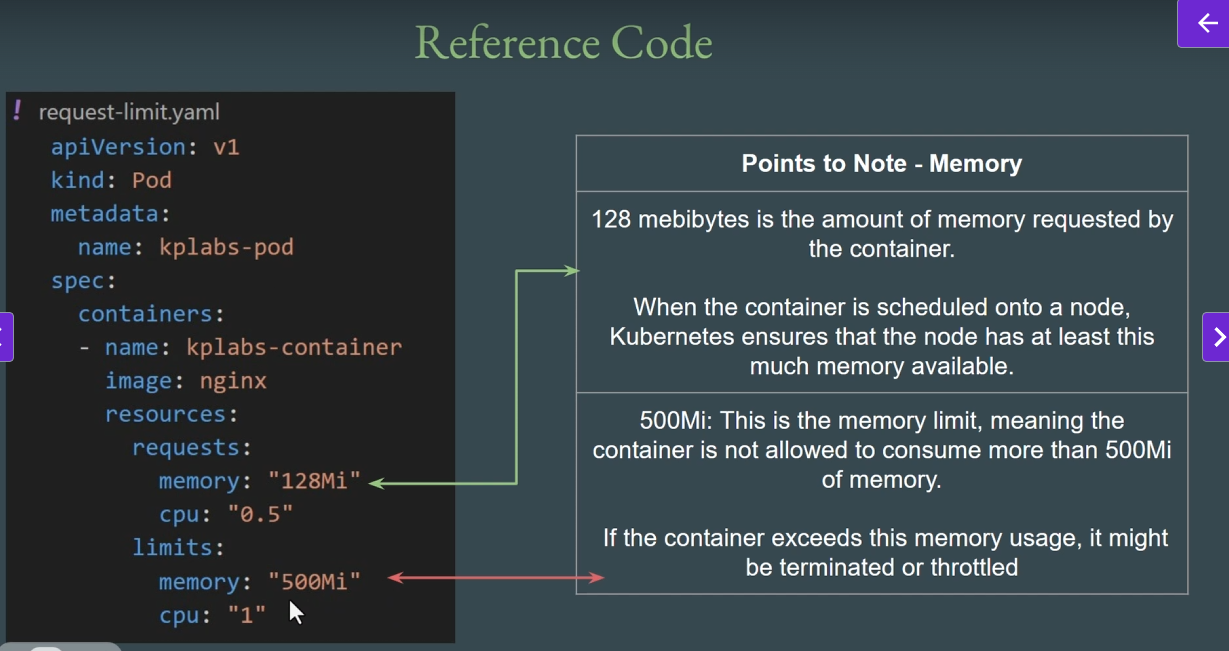
Requests and Limits
- worker node 내 resource를 많이 사용하는 특정 pod(app)이 있을 경우, 다른 pod들이 정상적으로 실행되지 않는 경우가 발생할수 있음
- 따라서 Pod별 필요한 resource를 Node에
Request/Limit으로 통보하여 Kubernetes가 적절하게 노드별 pod를 Scheduling함 -
link의 manifest 파일로
Request/Limit을 설정하여 컨테이너 내 생성되는 Pod의 Limit을 설정 가능 -
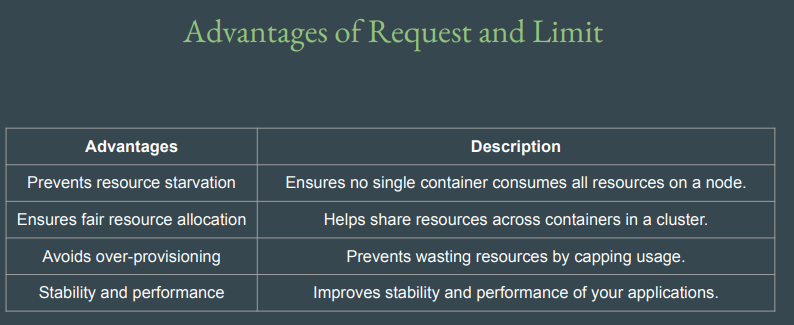
Request and Limit의 사용 장점은 아래 fig에서 확인 가능
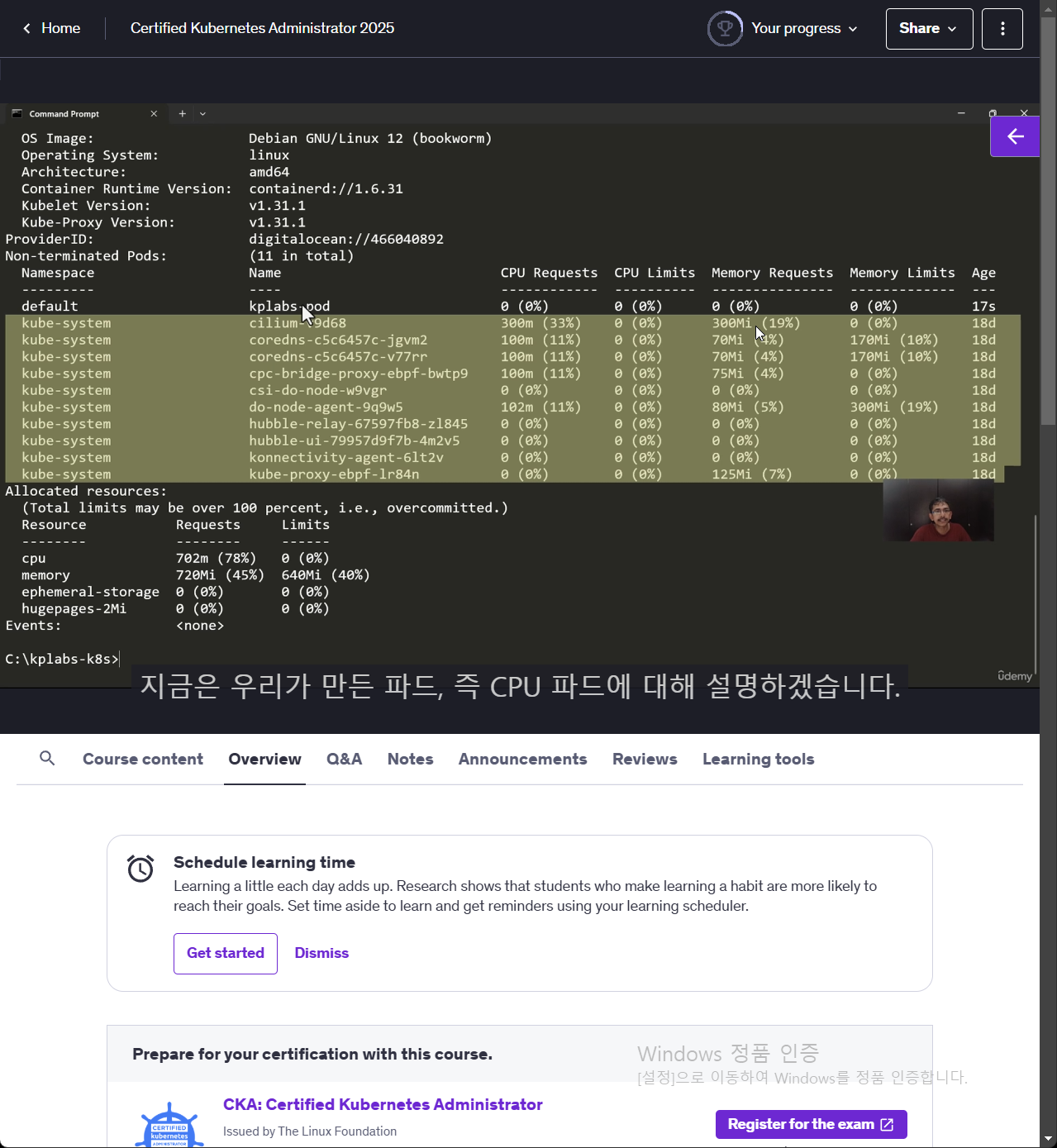
kubectl describe node (node-name)으로 확인해보면 kube-system은 digital-ocean에서 관리되는 kube-system을 제외하고 보면 request/limit으로 요청된 CPU/Memory 사항이 없는게 확인됨